

子图(Graph)与模块化复用
Graph 本身也是一个 Node,所以你可以把一组节点封装成子图,再把子图嵌进更大的工作流中。
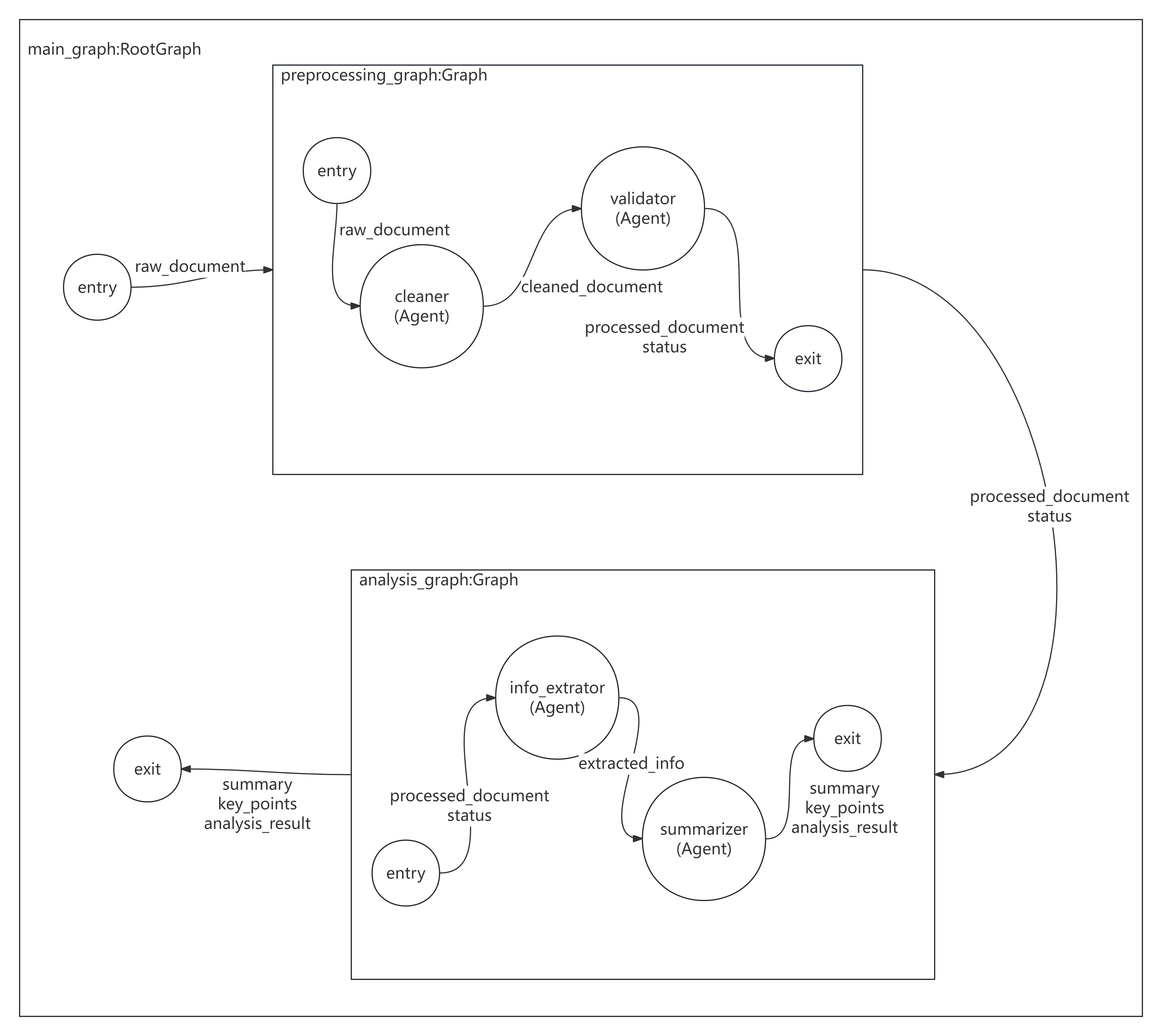
这个例子把“文档处理”拆成两个子图:
document_preprocessing:清理 + 校验content_analysis:提取 + 总结
消息传递视角
- 水平(Edge keys):主图与子图之间通过边字段显式对接(如
raw_document -> processed_document) - 垂直(attributes):可用于跨子图共享上下文;本示例以水平字段为主
示意图
示例代码(声明式 + NodeTemplate)
python
from masfactory import Agent, Graph, NodeTemplate, OpenAIModel, RootGraph
model = OpenAIModel(
api_key="YOUR_API_KEY",
base_url="YOUR_BASE_URL",
model_name="gpt-4o-mini",
)
BaseAgent = NodeTemplate(Agent, model=model)
DocumentPreprocessing = NodeTemplate(
Graph,
nodes=[
("document_cleaner", BaseAgent(instructions="你是文档清理专家,输出清理后的文档。", prompt_template="{raw_document}")),
("format_validator", BaseAgent(instructions="你是格式校验专家,输出处理后的文档与校验状态。", prompt_template="{cleaned_document}")),
],
edges=[
("entry", "document_cleaner", {"raw_document": "原始文档"}),
("document_cleaner", "format_validator", {"cleaned_document": "清理后的文档"}),
("format_validator", "exit", {"processed_document": "预处理完成的文档", "status": "校验状态"}),
],
)
ContentAnalysis = NodeTemplate(
Graph,
nodes=[
("info_extractor", BaseAgent(instructions="你是信息提取专家,输出结构化关键信息。", prompt_template="{processed_document}\n状态:{status}")),
("summarizer", BaseAgent(instructions="你是摘要专家,输出摘要、要点与完整分析。", prompt_template="{extracted_info}")),
],
edges=[
("entry", "info_extractor", {"processed_document": "预处理文档", "status": "校验状态"}),
("info_extractor", "summarizer", {"extracted_info": "提取信息"}),
("summarizer", "exit", {"summary": "摘要", "key_points": "要点", "analysis_result": "完整分析"}),
],
)
main = RootGraph(
name="document_processing_workflow",
nodes=[
("document_preprocessing", DocumentPreprocessing),
("content_analysis", ContentAnalysis),
],
edges=[
("entry", "document_preprocessing", {"raw_document": "原始文档内容"}),
("document_preprocessing", "content_analysis", {"processed_document": "预处理文档", "status": "校验状态"}),
("content_analysis", "exit", {"summary": "最终摘要", "key_points": "关键要点", "analysis_result": "分析结果"}),
],
)
main.build()
out, _attrs = main.invoke({"raw_document": "这里是一段待处理的文档内容……"})
print(out["summary"])示例代码(命令式,备选)
python
from masfactory import Agent, Graph, OpenAIModel, RootGraph
model = OpenAIModel(
api_key="YOUR_API_KEY",
base_url="YOUR_BASE_URL",
model_name="gpt-4o-mini",
)
main = RootGraph(name="document_processing_workflow")
# --- Subgraph 1: preprocessing ---
pre = main.create_node(Graph, name="document_preprocessing")
document_cleaner = pre.create_node(
Agent,
name="document_cleaner",
model=model,
instructions="你是文档清理专家,输出清理后的文档。",
prompt_template="{raw_document}",
)
format_validator = pre.create_node(
Agent,
name="format_validator",
model=model,
instructions="你是格式校验专家,输出处理后的文档与校验状态。",
prompt_template="{cleaned_document}",
)
pre.edge_from_entry(document_cleaner, {"raw_document": "原始文档"})
pre.create_edge(document_cleaner, format_validator, {"cleaned_document": "清理后的文档"})
pre.edge_to_exit(
format_validator,
{"processed_document": "预处理完成的文档", "status": "校验状态"},
)
# --- Subgraph 2: analysis ---
ana = main.create_node(Graph, name="content_analysis")
info_extractor = ana.create_node(
Agent,
name="info_extractor",
model=model,
instructions="你是信息提取专家,输出结构化关键信息。",
prompt_template="{processed_document}\n状态:{status}",
)
summarizer = ana.create_node(
Agent,
name="summarizer",
model=model,
instructions="你是摘要专家,输出摘要、要点与完整分析。",
prompt_template="{extracted_info}",
)
ana.edge_from_entry(info_extractor, {"processed_document": "预处理文档", "status": "校验状态"})
ana.create_edge(info_extractor, summarizer, {"extracted_info": "提取信息"})
ana.edge_to_exit(summarizer, {"summary": "摘要", "key_points": "要点", "analysis_result": "完整分析"})
# --- Wire subgraphs in main ---
main.edge_from_entry(pre, {"raw_document": "原始文档内容"})
main.create_edge(pre, ana, {"processed_document": "预处理文档", "status": "校验状态"})
main.edge_to_exit(ana, {"summary": "最终摘要", "key_points": "关键要点", "analysis_result": "分析结果"})
main.build()
out, _attrs = main.invoke({"raw_document": "这里是一段待处理的文档内容……"})
print(out["summary"])